MySQL-002 Tables & Keys
Tables
Definition: A table in an SQL database is a collection of related data entries and it consists of columns and rows. Tables are used to hold information about the objects that the database is designed to track.
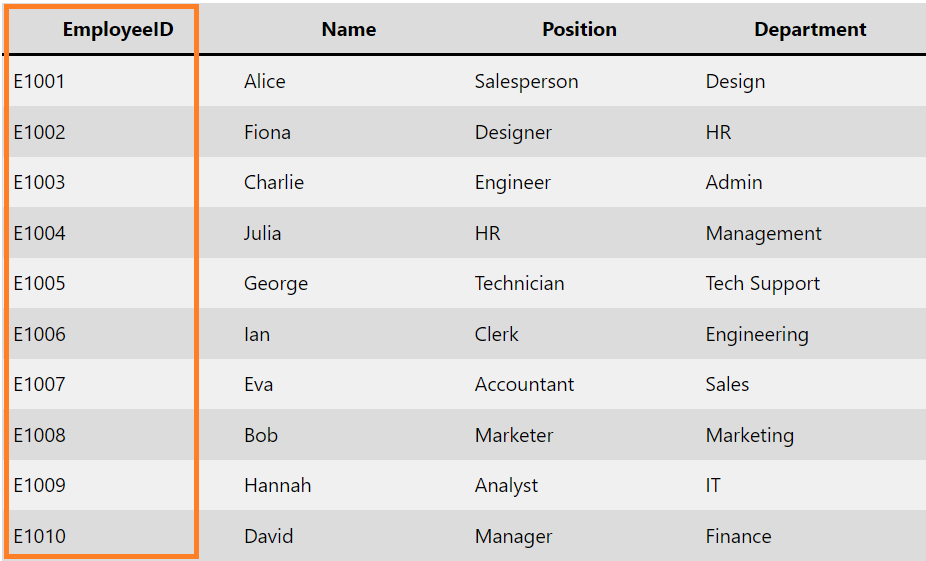
| EmployeeID | Name | Position | Department |
|---|---|---|---|
| E1001 | Alice | Salesperson | Design |
| E1002 | Fiona | Designer | HR |
| E1003 | Charlie | Engineer | Admin |
| E1004 | Julia | HR | Management |
| E1005 | George | Technician | Tech Support |
| E1006 | Ian | Clerk | Engineering |
| E1007 | Eva | Accountant | Sales |
| E1008 | Bob | Marketer | Marketing |
| E1009 | Hannah | Analyst | IT |
| E1010 | David | Manager | Finance |
Columns: Each column in a table represents a specific attribute or field of data. For example, in a table designed to store information about employees, the columns might include EmployeeID, Name, Position, Department, etc.
Rows: Each row in a table represents a single record. Continuing with the employee example, each row would contain the specific details for a single employee, such as their unique ID, name, position, and department.
Keys
Primary Key: Tables often have a primary key, which is a unique identifier for each record (row). This could be a single column (like EmployeeID) or a combination of columns. The primary key ensures that each record in the table is unique.
- Surrogate Key: A surrogate key is not derived from the data. In other words, it has no mapping to anything in the real word. It’s typically an artificial key that has no business meaning. For instance, it could be an auto-incrementing number, a globally unique identifier (GUID), or a random unique value.
- Natural Key: A natural key is based on one or more pre-existing data attributes naturally found within the dataset. For example, a Social Security Number (SSN) for individuals in the U.S., or a VIN (Vehicle Identification Number) for cars, can be considered natural keys.
Natural keys contrast with surrogate keys, which are artificially created for the sole purpose of uniquely identifying records in a table and do not have any inherent business meaning. The choice between using a natural key or a surrogate key depends on various factors like the stability of the data, the database schema, and the specific requirements of the application.
Foreign Keys: Tables can also have foreign keys, which are columns that link to the primary key of another table, establishing a relationship between the two tables.
Data Integrity: Tables enforce data integrity through constraints. These can include primary keys, foreign keys, unique constraints, and check constraints, ensuring the accuracy and consistency of data.
Schema: Tables are defined with a schema that dictates the structure of the table – the columns, their data types, and any constraints on the data.
Indexing: Tables can have indexes, which are used to speed up the retrieval of rows. An index is created on one or more columns of the table.
Relationships: Tables can be related to each other. These relationships are central to the relational database model and can be one-to-one, one-to-many, or many-to-many.